CS 222/322 - Machine Organization
Final Exam, Winter 1998
Wednesday, 18 March, 1:30-3:30 PM
7 problems on pages 1-2
- You may use the textbook, my class materials, any other published
material, and notes of your own. You definitely need the textbook.
- If you are not sure that you understand a question, please ask.
- There are 6 problems for Com Sci 222 and 322,
and one additional problem for Com Sci 322 only. Each numbered
problem is weighted equally for grading purposes.
- This problem covers some of the ideas in problem 2.3 of the
text, comparing a simple load/store instruction set to a
memory-memory instruction set for instruction bytes fetched and data
bytes fetched. Assume that load/store instructions are 4 bytes long
and memory-memory instructions are 8 bytes long. All data are 4
bytes long. Can load/store win on instruction bytes fetched? Can
there be a tie? Can memory-memory win? Answer the same three
questions for data bytes fetched.
- Look at the table describing the simple DLX pipeline that I
provided on the Web. Create a new column for the table, defining a
memory-memory data transfer instruction (it transfers a word of data
from one memory address to another). Stick to the simple spirit of
the table--no forwarding at all. Compare the performance of the new
instruction to a LOAD followed by a STORE. How does the comparison
change with aggressive forwarding?
- Describe 3 ways in which a larger cache block size can improve
uniprocessor performance, and 3 ways in which a larger cache block
size can harm performance. One sentence should suffice for each of
the 6 points. You can solve this problem without knowing the write method.
- In a modern microprocessor, the memory hierarchy provides
three different places to look for a given memory address: TLB,
cache, and main memory. If each of these were completely
independent, there would be 8 possible states for a memory address
in the microprocessor. But, not all 8 states are possible. Which 3
are impossible if the cache uses physical addresses? Which of these
becomes possible if the cache uses virtual addresses?
- In this problem, all frequencies are based on the uniprocessor
dynamic instruction stream. You have a computer with 100
microprocessors. You are running a program that is 5% inherently
sequential. The remaining 95% of the program is capable of using
all 100 processors, but at a cost in synchronization and contention
overhead. With P>1 processors in action, the CPI increases by a
factor of
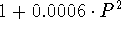 . What number of processors will run
the program as fast as possible? What is the speedup over sequential
processing with that number of processors?
. What number of processors will run
the program as fast as possible? What is the speedup over sequential
processing with that number of processors? - You have a multiprocessor using write-back, write-invalidate,
write-allocate for snoopy cache coherence. In addition to the snoopy
bus, there is a second nonsnoopy bus, where each message is read by
only one CPU or by the memory. What messages can go on the nonsnoopy
bus? How does this change if you switch to write-update?
- In problem 5, I chose to make the synchronization and
contention overhead proportional to
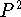 rather than to P for two
reasons--one has to do with realism and the other has to do with
making the problem interesting. What were my two reasons? That is,
why is it superficially reasonable to expect the overhead to be
proportional to ? And, how does part of the problem trivialize
when overhead is proportional to P?
rather than to P for two
reasons--one has to do with realism and the other has to do with
making the problem interesting. What were my two reasons? That is,
why is it superficially reasonable to expect the overhead to be
proportional to ? And, how does part of the problem trivialize
when overhead is proportional to P?
This document was generated using the LaTeX2HTML translator Version 96.1 (Feb 5, 1996) Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 final.tex.
The translation was initiated by Mike O'Donnell on Thu Mar 11 21:27:32 CST 1999
Mike O'Donnell
Thu Mar 11 21:27:32 CST 1999